HotChips 2023 was held August 27-29, 2023 at Stanford University in California and was the first in-person version of the conference in 4 years. The conference was held in a hybrid format that had over 500 participants in-person and over 1,000 attending virtually online. Topics covered a broad range of advancements in computing, connectivity, and computer architecture.
Both AMD and Intel gave presentations on their new server class processors. I found these talks interesting for several reasons, but primarily for the decision that they each made to produce a performance version and an energy efficient version of their cores for the server market.
We can go back to ARM’s big.LITTLE concept from over a decade ago and MediaTek’s Tri-Gear designs that used different cores with different power vs. efficiency profiles to achieve better performance and power efficiency. Some key differences here though are that those cores were targeted for the mobile application processor market and were implemented together on the same piece of silicon. The new cores announced by AMD and Intel are targeted for servers and currently are not implemented side by side on the same chip.
Another similarity between the two companies’ solutions is the use of chiplets for the core complex dies that plug into a platform framework using separate I/O dies to connect the system together.
Chris Gianos, Intel Fellow, presented the slide below in figure 1:
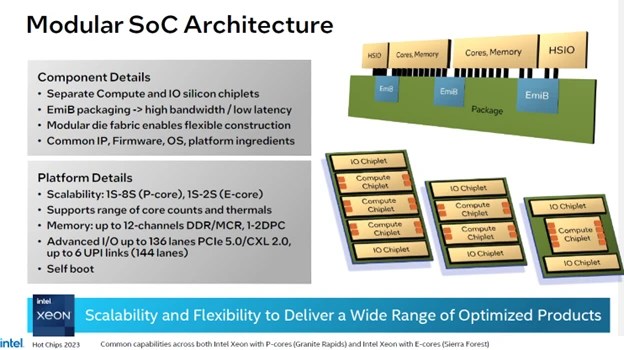
Fig. 1: Intel modular SoC architecture.
This slide diagrams the way that compute chiplets can be added to the system to generate different products. The P-Core, used in Granite Rapids, is “drop-in” compatible with their E-Core used in Sierra Forest. The two cores are different designs though that were specifically targeted towards performance and efficiency respectively. The E-Core doesn’t include AVX or AMX instructions that are found in the P-Cores as customers need to decide in advance how much performance per core they need and what types of applications they want to run.
Kai Troester, AMD Fellow, presented their Zen 4 core along with Ravi Bhargava, AMD Sr. Fellow. Zen 4, compared to previous generation AMD cores, has larger and improved conditional branch predictors with improved fetch bandwidth of up to 2 taken branch predictions per cycle. A larger op cache for improved redirect latency and power is also incorporated. Zen 4 includes AVX-512 support and with V-cache, up to 96MB of L3 per 8 cores.
Zen 4c is a compact version of Zen 4, optimized for density and power efficiency. It has the same IPC and features of Zen 4 with a lower max frequency, smaller area, and increased power efficiency. Zen 4c can contain 33% more cores in the same power envelope and IPC as Zen 4. Kai said it’s, “the same core (as Zen 4), but smaller because it has a lower frequency target so it’s more power efficient.” The diagram from his presentation is shown below in figure 2 and it shows the tradeoffs in terms of frequency for the advantages in area and power efficiency.

Fig. 2: Zen 4 vs. Zen 4c IPC, frequency, area, and power efficiency tradeoff.
AMD has already used chiplets as part of their system architecture and continues that practice using Zen 4 performance cores for their Genoa parts with up to 96 cores and Zen 4c efficiency cores for their Bergamo parts with up to 128 cores. The diagram below in figure 3 shows how the two cores can be used in the same system framework to produce different products better targeted for specific markets.

Fig. 3: Zen 4 vs. Zen 4c configuration.
Ravi mentioned that the common I/O Die continues to build upon AMD’s Infinity Fabric to scale across multiple core complex dies to create a broad family of server parts.
Dan Soltis, Sr. Principal Engineer at Intel, said that the E-Core used in Sierra Forest incorporates dual 3 wide out of order decoders that are more power efficient and have better latency than a single 6 wide decoder. The E-Core is also a single-threaded core (another difference from the P-Core). For a chiplet with 4-cores + L2, all these components are on the same clock and VDD and the L2 is the interface to the mesh, so all 4-cores would dynamically voltage and frequency scale (DVFS) together. Dan also presented the slide shown below in figure 4 that represents the tradeoff in performance and efficiency between the new P-Core and E-Core and the older Sapphire Rapids core. The chart also shows the ~2.5x scaling improvement going from Sapphire Rapids to Sierra Forrest.

Fig. 4: Intel’s P-Core and E-Core deployment view.
In figure 4, designs that are up and to the right are superior to others. This shows the advantage that the E-Core (Sierra Forest) systems have in terms of efficiency and the relative performance advantage of the P-Core (Granite Rapids).
The use of chiplets by major server CPU providers has allowed a greater capability to tailor parts for different markets and the use of differentiated cores expands upon that capability to better address different market needs. It should be exciting to watch these products compete in the marketplace and how the underlying chiplet framework will enable more innovation and tailoring to address new markets in the future.
This article originally appeared on Semiconductor Engineering